A grammatical Error Analysis of final year students' Arabic writing
1. INTRODUCTION [1]
The Arabic Undergraduate Programme at the University of Leeds involves teaching Arabic to complete ab initio students who know no Arabic when they start level one. The programme involves the following degree combinations:
- Single Honours: BA in Arabic and Middle Eastern Studies.
- Single Honours: BA in Arabic and Islamic Studies.
- Joint Honours: BA in Arabic and any other foreign language such as French, Spanish, Chinese, Italian.
For all of the above programmes, there is a high number of contact hours in year one, and a compulsory year abroad in year two. In year three, students study two compulsory Arabic modules: Essential Skills in Arabic (ARAB2020/2021) and Advanced Arabic and Grammar (ARAB2010/11). In their final year, they study one compulsory module: Advanced Skills in Arabic Language (ARAB3020). Arabic Stylistics (ARAB3010) is only compulsory for Single Honours. Joint Honours students choose to study Advanced Media Arabic (ARAB3888) or Arabic Stylistics (ARAB3010) as optional modules. Below is a summary of the contact learning hours, including the contact hours for each year:
Year 1: 400 learning hours (including 168 contact hrs)
Year 2: Year Abroad 1200 learning hours (including 464 contact hours)
Year 3: 400 learning hrs (including 84 contact hrs)
Year 4: 200 learning hrs (including 42 contact hrs)[2]
All the students start as complete beginners, and they are taught almost the same number of contact hours throughout their study, therefore they progress at a similar pace. Given, on this basis, that all year-four students can be expected to be at a similar level, this paper will focus on the classification of the most common errors that year-four students make when they write assessed Arabic essays. It will attempt to categorise, describe, and explain these errors and recommend ways to tackle them in designing the teaching materials for ARAB3020, reviewing them and/or their methodology.
Pedagogically, Error Analysis (EA) can be helpful in addressing certain areas:
- weak areas which need to be enhanced by introducing new materials;
- lexical or grammatical items which could need to be taught later;
- missing grammatical elements which lead students to have recourse to alternative structures;
- teaching items which have not been included in the syllabus, but are necessary at this stage;
- lack of organization and gradation in the syllabus or omission of important items;
- weaknesses or errors which may be entirely new to the teacher or of which s/he may be only dimly aware (Etherton, 1977:67-68).
2. THEORETICAL FRAMEWORK AND METHODOLOGY
Error Analysis (EA) is defined as ‘the technique of identifying, classifying and systematically interpreting the unacceptable forms produced by someone learning a foreign language using any of the principles and procedures provided by linguistics’ (Crystal, 2003:165). It has been the subject of interest of many scholars since the past century (Corder, 1967, 1971 1981; Richards, 1971, 1984; Richards et al. 1992 and James, 1998, among others). It emerged in the 1960s as a reaction to the Contrastive Analysis (CA) interference hypothesis: ‘the novelty of EA, distinguishing it from CA, was that the mother tongue was not supposed to enter the picture. The claim was made that errors could be fully described in terms of the target language (TL), without the need to refer to the L1 of the learners’ (James, 1998:5). EA, however, plays a complementary role to CA (Candlin, 1974:9). Thus, the latter highlights the problematic areas which face the students whereas the former provides confirmation for the teacher as regards to what has yet to be learned (Candlin, cited in Jassem, 2000: 43). For the purposes of this study, EA, then, is viewed more in terms of its usefulness as a methodology of analysing data than as a theory of acquisition (Cook, 1993:22). EA has existed in the Arabic tradition for almost 12th centuries, classical Arabic grammarians distinguishing between غلط (mistake or error) and زلة لسان (slip of the tongue). They defined errors as incorrect uses of language due to misperception (Ibn Makkī, cited in Jassem, 2000: 99). ‘In the area of EA of language in the teaching the Arabic language, few attempts have been made, all of which are limited to the area of teaching Arabic language to foreigners’ (Jassem, 2000:7).
Although ‘errors do not seem to submit themselves to any precise systematic analysis’ as Jain (1984:190) argues, one can assume that common errors in Arabic writing can be caused by (i) asymmetry between English and Arabic grammar and stylistics; (ii) lack of focus on Arabic grammar by English students; (iii) lack of motivation and interest in some topics taught (e.g. advanced grammar), which leads to ‘incomplete application of the rules and failure to learn conditions under which rules apply’ (Richards, 1984:174); and (iv) mother-tongue interference, which is ‘ubiquitously and patently obvious’ (James, 1998:5). Thus, the reasons for the occurrence of the errors are possibly to do with language one (L1) or language two (L2), there being no clear-cut distinction between these two categories: ‘the phenomenon of errors caused by cross-association of both L1 and L2 also seem to exist’ (Jain, 1984:190).
2.1 Types of errors
This study is concerned with the systematic errors rather than lapses occurring due to wrong usage or non-systematic mistakes occurring due to bad performance. Applied linguists distinguish between competence and performance errors; the former are caused due to lack of knowledge of grammar, vocabulary and misunderstanding of the appropriate structure of the TL, whereas the latter reflect other aspects such as tiredness, nervousness, or laziness (Corder, 1973). They also distinguish between global and local errors: the former can hinder understanding of the message and include such things as wrong word order, overgeneralising a rule to exceptions, and wrong sentence connectors. The latter, on the other hand, do not affect the overall understanding but involve single constituents (Dulay, Burt and Krashen, 1982: 191) such as incorrect noun and verb inflections, and concord, among other things (Riddell, 1990:29-30).
In this paper, errors are classified into the following types: grammatical, typographical, discourse-level and lexical (refer to table 1 in section 3 below). Grammatical errors are the most common errors identified in the data. For the purposes of this paper, I will focus on the grammatical errors occurring in the written production of the student group being analysed.
2.2 Method of analysis:
As the study adopts an EA approach, I will know outline the main stages of carrying out such an analysis as identified by Corder (1974) and Ellis (2008) and further explained by James (1998):
- Collection of the data
- Error identification and description
- Explanation of Errors for the purpose of categorising them
- Evaluation of Errors and diagnosis
These elements will be discussed in further detail in sections 3-3.5.
3. ANALYSIS OF DATA
In this section, I will discuss the quantitative and qualitative analysis of data as per the above elements.
3.1 Collection of Data
Formally assessed written productions will be used as sample material. The aim of choosing to analyse assessed writing is to guarantee that students produce roughly the same word count, and for all of the participants to write about the topics allocated to them. Only material from native speakers of English enrolled on Single Honours degree will be analysed to minimize interferences from other foreign languages. Three written Arabic essays, of 500 hundred words each, were collected from twelve students over a number of months during the students’ study of Advanced Skills in Arabic Language (ARAB3020). Thus, the total number of collected essays is thirty-six, and the overall number of words approximately 18,000.
3.2 Error Identification
As noted in Section 2.1, the study will focus on ‘systematic errors’ in the final-year students’ writing not on ‘mistakes’ or ‘slips’ that might occur whilst decoding or articulating speech. One example of ‘slips’ in final-year students’ Arabic writing is misspellings, which tend to occur due to the misuse of dots in Arabic. Students type many words using the wrong dots, which results in meaningless words as in the word ‘history’ being written as ناريخ instead of تاريخ, or the word ‘huts’ as اكواج rather than أكواخ. In the error-identification phase, categories and subcategories of errors will be identified.
I have undertaken a quantitative frequency analysis of the errors, using simple statistical methods for identifying and categorising the errors, counting them and calculating the percentages for each category as in the following table:
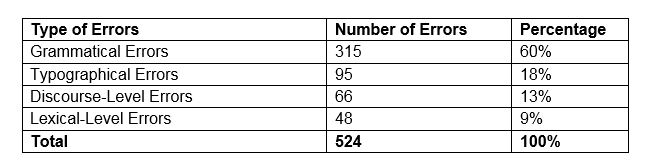
Table 1: Quantitative Analysis of Final Year Students’ Errors
As shown in Table 1, grammatical errors are the most frequent types: 60% of all errors. In second place come typographical errors (e.g. spelling errors) at 18%, followed by discourse-level errors, i.e. the textual and stylistic errors at 13%. Finally lexical-level errors (e.g. the choice of inappropriate terms, incorrect collocations) are 9% of the total. This article will only discuss errors at the grammatical level. The grammatical subcategories analysed in this paper include:

3.3 Error Description and Explanation
The purpose of this stage is to describe errors and attempt to answer questions on how and why certain errors are committed and possibly trace the sources of these errors, this last goal being ‘the ultimate object of EA’ (Corder, 1981:24). Analysis will be based on the figures presented in Table 1 above.
3.3.1 The Level of Grammar
In this section, I will analyse the common errors on the grammatical level and will attempt to explain the reasons behind them. Table 2 below provides the frequency analysis of the errors:
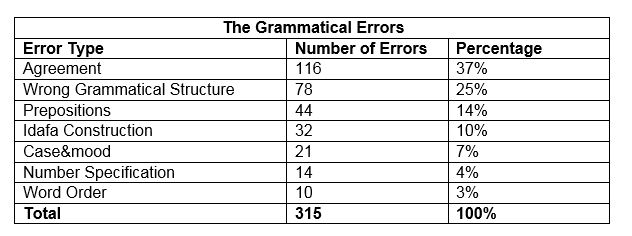
Table 2: Frequency Analysis of the Final year students’ Grammatical Errors
As the above table shows, agreement (37%) and wrong grammatical structure (25%) are the most frequent areas in the final-year students’ writing. Prepositions (14%) and the idafa construction (10%) are the second most frequent areas. Other less frequent areas are case&mood (7%), number specification (4%) and finally word order (3%). These grammatical subcategories will be discussed below.
3.3.1.1 Agreement
This category involved the highest percentage of grammatical errors in final-year students’ writing. There are a number of agreement types in Arabic; this paper will only focus on the common errors involving certain types of agreement identified in the data: gender, number, and definiteness. Below is a brief explanation of these types:
- Subject-verb agreement: In Arabic, verbs must agree with the subject in number, i.e. (singular, dual or plural) and in gender (i.e. masculine or feminine). In the case of verbal sentences (when the verb precedes the subject), verbs must agree with the subject in gender only but not in number, all post-verbal subjects being in the singular.
- Noun-Adjective agreement: In an Arabic noun phrase a noun may be followed by one or more adjectives (attribution). Adjectives may also be related to noun-phrases in verbless predicand-predicate (topic-comment) sentences (predication) (Dickins, 2010:240). Adjectives modifying a noun in both attribution and predication structures agree in gender (i.e. both are masculine or feminine), number (both are singular, dual or plural), definiteness (i.e. both are definite or indefinite) and case (i.e. both are nominative, accusative or genitive). In a demonstrative phrase which consists of demonstrative pronoun, a noun and possibly an adjective, all of these elements agree in gender, number, definiteness, and case (although case, in particular, is not marked on most demonstratives) (Alhawary, 2011:76).[3]
- Deflected agreement: In Arabic, inanimate plural nouns follow feminine singular agreement in both subject-verb agreement and noun-adjective agreement.
Common agreement errors in students’ writing can be divided into gender, number and definiteness as in the table below:

Table 3: Agreement errors in final year students’ writing
Table 3 above gives three types of agreement errors: gender agreement errors constituted 22% of agreement errors (these constituting 34% of errors overall), number agreement errors constituted 7% of agreement errors and definiteness errors constituted 5%. Below are examples of subject-adjective agreement errors (first example) and subject-verb gender agreement errors (second example):

Table 4: Gender agreement errors
The above two errors have the same cause. According to Ryding (2005:243) ‘non-human plural nouns require feminine singular agreement’ or as she calls it ‘deflected agreement’. Thus the broken non-human plural noun الأنظمة / regimes, in the first example above, should take the singular feminine adjective العربية /the Arabic and noun الأشعار / poetry (plural), in the second example, should take a singular feminine verb تؤكد / it confirms rather than a masculine singular verb يؤكد / it confirms. It is worth mentioning that both these examples involve gender and number agreement, the latter will be discussed further in the following section.
Number agreement
Arabic grammar identifies two types of sentences, verbal sentences (starting with a verb) and nominal sentences (starting with the ‘predicand' (as a translation of المبتدأ) and a 'predicate' as a translation of الخبر. This provides distinct terminology in English for what are distinct terms in Arabic (Dickins, 2010). In verbal sentences, the verb agrees in gender but not in number (verbs in verbal sentences are always in the singular). However in nominal sentences, the verb that follows the subject must agree in both number (singular, dual and plural) and gender (masculine or feminine), except in cases of ‘deflected agreement’ (see above). This is explained in the table below:
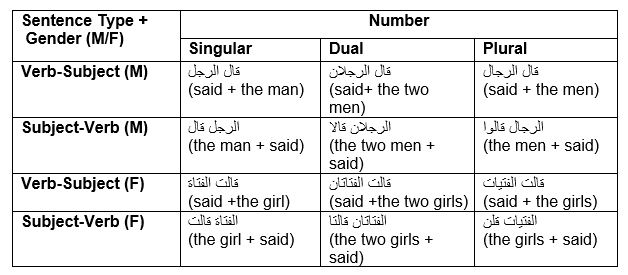
Table 5: Number agreement in Arabic
Below are two examples of the errors identified in the data:

Table 6: Number agreement errors
In the first example, the verb should agree in number with the predicand الدروز / Druze by adding a plural pronominal suffix to the verb: لم يشاركوا / they did not participate. In the second example, there is no agreement required (the verb should be in the 3rd person masculine singular) because the sentence starts with the verb, أعلن/ declared, but students did not apply this rule and followed the common rules of subject-verb agreement.
Definiteness:
As mentioned above in agreement, the subject agrees with the adjective (s) in definiteness (i.e. both are definite or indefinite): بيت أبيض كبير / a big white house orالبيت الأبيض الكبير / the big white house. Below is an example of this subcategory in the data analysed:

Table 7: Definiteness errors
In the above example, the noun phrase consists of a definite head noun المواطن / the citizen followed by two adjectives:مصري / Egyptian an سوري / Syrian. Both adjectives are indefinite, but should be definite to agree with the definite noun. That is, they should be المصري/ the Egyptian and the السوري / the Syrian.
3.3.1.2 Wrong grammatical structures
Errors in this category can be further classified into a number of subcategories. The first sub-category is the replacement of a verb phrase by a verbal noun and the use of the passive participle instead of the past tense form of the verb:
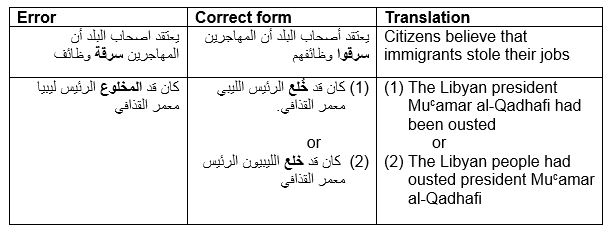
Table 8: Wrong grammatical structure: Replacement of a verb phrase by a verbal noun and the use of the passive participle instead of the past tense
Another sub-category is the replacement of an imperfect tense form of the verb by a nominal form (verbal noun) as in the following:

Table 9: Wrong grammatical structure: Replacement of the imperfect tense form of the verb by a nominal form (verbal noun)
A third category involves omission of the imperfect verb after the infinitival particle ‘an as in:

Table 10: Wrong grammatical structure: Omission of the imperfect verb after the infinitival particle ‘an
The above example shows an error in the use of a modal- phrase. Modal verbs and other modal phrases, take an imperfect subjunctive form of the verb after the infinitival particle ‘an. The examples also show a problem in word order in putting these modal elements together as in:

Table 11: Structure of the modal phrase in Arabic
There are other errors to do with the passive structure (as in examples 1 and 2) and quasi-passive structure (as in example 3):
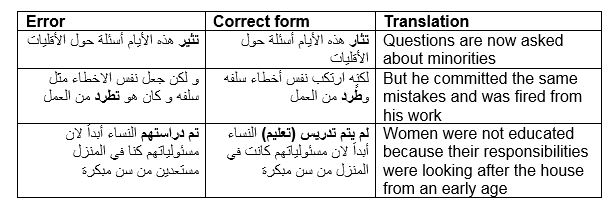
Table 12: Wrong grammatical structure: Passive structure and quasi-passive structure
The first example above shows that students may not know how to change hollow verbs (verbs whose middle root consonant is ‘w’ or ‘y’) into the passive. The second example is a bit unexpected because it is a form-one (i.e. basic) verb and changing it into passive is straightforward. But the wording of the whole sentence is problematic and affects the entire meaning of the sentence. The same applies to the last example where the candidate opts for the quasi-passive structure commonly used in the language of media and is done through: (تم + مصدر - to be done/made/concluded). ‘The verb tamma is passive in sense, though its vowelling is that of an active verb…’ (Ashtiany, 1993:29).
3.3.1.3 Prepositions
Prepositions are defined by Badawi, Carter and Gully (2004:175) as ‘particles that precede the noun’. Prepositions are sometimes followed by pronouns and question words (Alhwary, 2011:119). Nouns following prepositions take the genitive case ending (ibid.) In Arabic as in English, prepositions contribute to meaning by referring to location, direction, space, time, or reason. They may also be used in abstract or figurative ways, in idioms and expressions or may occur in combination with verbs to convey a particular meaning specific to that combination (Ryding, 2004:366, Alhawary, 2001:126)[4]. The restricted usages and senses of prepositions implies that prepositions can be categorised as both lexical and grammatical.
The data involves two types of preposition errors: grammatical errors where the preposition is omitted or added and lexical errors where the wrong preposition is used. Below are two examples of grammatical errors which involve missing out a preposition (as in example one), or adding a preposition which is not needed (as in example two):

Table 13: Preposition errors
In the first example above, a preposition is omitted in the phrase من الاثار الرئيسية الربيع العربي / the negative effects [preposition missing] the Arab Spring, which should be من الاثار الرئيسية للربيع العربي / the negative effects of the Arab Spring. In the second phrase الاطاحة هذه الانظمة / ousting [preposition missing] these regimes. The verb أطاح/ to oust takes the prepositionب / bi: الاطاحة بهذه الانظمة / ousting these regimes. The demonstrative pronoun follows the verb so the preposition is attached to it. In the second example: استعمار لهذا الأرض/ to colonise for [preposition added] this land, the preposition ل / li (for) is added to the verbاستعمر / to colonise which does not take a preposition. This error could be interpreted based on the student’s muddling up two possibilities:
- The simple idafa (genitive) with a verbal noun: استعمار هذه الأرض
- The use of a subjective genitive plus ل to introduce the equivalent of the object with a verbal noun: استعمار مجموعة اوربية لهذه الأرض
3.3.1.4 Idafa construction
Arabic distinguishes simple idafa constructions which are similar to the simple ‘s’-possessive structures in English such as جامعة ليدز / the University of Leeds where the head noun (the annexation-head) (Dickins, 2013:59) is جامعة / University and the modifier (annex) (Watson, 1993:173) is ليدز / Leeds, and compound idafa constructions, involving recursion, such as جامعة ليدز طلاب / the students of the University of Leeds, where the primary head noun (primary annexation-head) is طلاب / students, and the primary modifier (primary annex) is the phrase جامعة ليدز / University of Leeds, but where this primary modifier (primary annex) can itself be further analysed into a secondary annexation-head (second annex) جامعة University and a second modifier (secondary annex) ليدز / Leeds.
What makes an idafa construction hard to learn (apart from the possibility of structural recursion) is the specific rules for forming it and the forms it takes. In an idafa construction the head (annexation-head) is always indefinite in form (i.e. it lacks the definite article ال/al-), while the modifier (annex) may be indefinite, as in كتاب طالب / a student’s book (where طالب / student is indefinite) or definite as inكتاب الطالب / the student’s book (where الطالب has the initial the definite article ال al-). In a compound idafa, the last word of the idafa construction (the ultimate modifier / annex) may be indefinite or definite in form, while all the words before it are necessarily indefinite in form:كتاب طالب جامعة القاهرة / the book of the University of Cairo student. The latter construction is more challenging and is a recurring error in the data:

Table 14: Idafa construction errors
The above example shows that the students generalise the rule of the simple idafa to the compound idafa, starting the structure with an indefinite noun and making all the following nouns of the idafa construction definite.
The errors identified in the data suggest that the idafa construction is an area of Arabic grammar which continues to cause difficulty for students, although the idafa is one of the grammar areas which is taught very early on at Level One in the degree, because it is one of the most commonly recurring structures in Arabic.
3.3.1.5 Other less common grammatical errors
In this section, I will discuss the subcategories of Arabic grammar errors which were less frequent in the final year students’ data, namely: number specification, case&mood and word order. Although these categories were less frequent, they seemed to be challenging and require more focus in the preparation of materials and in teaching Arabic grammar, writing and translation. They are discussed with illustrative examples:
Number specification
‘Specification’ (تمييز الكلمة / word specification) involves an accusative noun that disambiguates a word which precedes it. An example is لتراً حليباً / a litre of milk, in اشتريت لتراً حليباً / I bought a litre of milk. Note also that in this example, the form with the genitive لتر حليبٍ is also possible. This type of specification disambiguates measurements, weight or space. Another form of specification is number specification, in which an indefinite word (the counted noun) disambiguates a number preceding it. Arabic has specific rules for number specification which are now taught as part of grammar in schools. Alhawary (2011, 373) states that:
there are three rules involved in the use of both parts of the number phrase (the number/numeral) and the ‘counted noun’ with respect to:
(a) whether the counted noun following the number is singular, dual or plural;
(b) the type of case ending on the number and
(c) the type of case ending on the counted noun.[5]
In their final year writing, many of the students’ errors have to do with the case and number of the counted noun itself. Below are a few examples:

Table 15: Number specification errors
The above three examples involve different rules depending on which number precedes the specification word. The first example illustrates the group of numbers between three and ten. The counted noun for this group of numbers is always in the genitive plural and the number itself must disagree in gender with the counted noun (thus if the counted noun is masculine in its singular form, the number itself must appear in the feminine form, and vice versa). Thus the correct form is ثلاثة أقسامٍ/ three parts rather than ثلاثة قسم/ three part (i.e. the word أقسامٍ ‘parts’ has to be in the plural, while the number ثلاثة ‘three’ has to be in the feminine form, because the word قسم ‘part’, i.e. in the singular, is masculine).
The second example illustrates the fact that the counted noun for numbers eleven and twelve is always accusative singular and that it agrees in gender with the number; so the correct form is not اثني عشرة مخيمات/ twelve camps, it is rather اثنا عشرَ مخيماً/ twelve camp. In the third example, the counted noun for the number million is always in the genitive singular. Thus, the correct form is 1.6مليون مسلم / 1.6 million Muslim, not 1.6 مليون المسلمين / 1.6 million the Muslims.
Case&mood and word order
Other less frequent errors include case, mood and word order. Examples of case and word order are given on the table below. Mood errors were very minor in the data and all of the errors found involved errors in the subjective mood following the particle ‘an.[6]
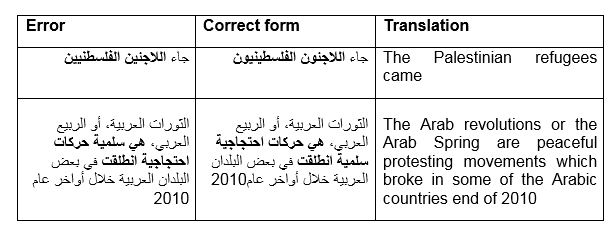
Table 16: Case and word order errors
The first of the two examples above involve an example of case error. The subject phrase (noun plus adjective) is in the accusative case but should be in the nominative. This type of error varies form one student to another and can also be committed by native speakers (since case-endings are features of Standard Arabic, which Arabs learn at school, but not of their native colloquial dialects, which are their mother tongue.
The second example involves an error in word order in which the student muddles the word order in the long noun phrase, consisting of one head noun حركات / movements and two adjectives احتجاجية /protest-related, protestory, andسلمية / peaceful. In a noun phrase in Arabic, adjectives follow the noun but in the above examples, the student puts the adjectiveسلمية / peaceful first followed by the noun then followed by the second adjective احتجاجية / protest-related, protestory. It is hard to explain this error. It is unclear whether it is to be regarded as being caused by L1 interference, or if it is to do with the complex structure of the noun phrase.
3.4 Conclusion and Recommendations
This paper has discussed errors in final year students’ Arabic writing. It has analysed frequency of errors at different levels: grammatical, typographical, lexical and textual. Grammatical errors were discussed in detail as they are the most common errors in the data analysed. In the following paragraphs, I will suggest some ways for dealing with the errors involving the grammatical subcategories discussed in class and outside class.
Errors at the grammatical level include subcategories which are taught at beginner’s level: gender agreement, number agreement and definiteness and the idafa construction. Other common errors involve more advanced grammatical subcategories which also involve areas of difference between English and Arabic grammar. These are passive, modal auxiliaries, and number specification. Another common grammatical subcategory where errors occur is prepositions, an area which is taught at different levels throughout the whole degree.
Gender agreement is an area of difference between English and Arabic. English operates almost entirely with natural gender and gender agreement is essentially confined to pronouns. Arabic, by contrast, has grammatical gender, with complex gender agreement patterns. Unsurprisingly, given these differences, learners of Arabic at the University of Leeds continue to get confused and commit errors even at an advanced level of learning. Sometimes it can be hard to dedicate time to basic aspects of grammar aspects at advanced levels because more focus is given to other advanced aspects of grammar. As the figures and analysis have shown, there are certain areas of agreement which need more effort on the part of Arabic teachers such as deflected agreement. This could be revised and reinforced in teaching activity Arabic modules; more focus could be given to this issue in speaking classes, and in oral and written feedback on written tasks.
Prepositions are an under-considered area of Arabic grammar and reading/writing classes. Students are expected to learn prepositions on a fairly ad hoc basis as they progress in their degree. This may be attributed to the fact that there is no one method of teaching prepositions. Rather, they need to be practiced at all stages of the degree. More attention should be given to them in reading and writing by devoting more time for practice in class through error analysis exercises involving students’ writing, gap-filling exercises involving phrasal verbs, and reading in class to identify collocations involving prepositions and verbs, nouns and adjectives. Teachers could also prepare a bank of online exercises and/or quizzes on a variety of topics related to the students’ reading and writing syllabus. The work done in the media Arabic syllabus could be of value to the teaching and learning of advanced reading and writing classes.
Basic grammar structures such as the idafa construction are an area of Arabic grammar which is taught at BA level one. But students continue to make errors in their writing at more advanced BA levels. This suggests that this area is to be revisited at all levels in teaching the different skills for Arabic. Students could be assigned home-work activities and autonomous online learning drills and exercises.
Grammatical structures taught at the advanced level such as modal verbs and phrases are areas of difference between English and Arabic grammar and cause difficulty for Arabic learners. These structures are taught at BA level two. They recur in different text types and are challenging to learn. Using the traditional grammar-translation approach in teaching them is not helpful. They need to be taught using innovative communicative teaching methods and to be embedded in the teaching and learning of the four language skills and in Arabic media and translation classes. Using parallel Arabic-English texts and various examples from different text types may also help students figure out differences between the two languages.
Other less frequent subcategories in the data analysed are case, mood and word order and number specification. This last is an area of significant difference between English and Arabic grammar. Although it is one of the less frequent areas in the data analysed, based on my experience in teaching it in advanced media Arabic, it is a recurring area in Arabic media texts and students find it challenging. It is taught at the intermediate and advanced levels and requires more practice than it is currently given. It should not be taught in grammar classes only but also integrated with the teaching of the four basic skills. Based on my experience of teaching Arabic grammar and writing, I can confirm that as with many other areas in Arabic grammar, it is not easy to teach number specification by following traditional grammar methods. Rather it is better to teach it through language-in-context activities. This is one of the areas which need to be revisited and included in the syllabus design of other advanced Arabic modules (e.g. in translation, media Arabic).
In summary, it was clear during the process of the data analysis that some students commit more errors than others. These students need to be monitored and be given more support by assigning them further work to enhance their grammar and writing skills. Finding out the needs and learning strategies of these students could be very helpful in finding out how they could be better supported. Adopting innovative ways of teaching Arabic grammar in context rather than relying on outmoded grammar-based methods can certainly help to overcome the challenges which Arabic learners encounter. Monolingual corpora and parallel corpora are other useful tools to help in teaching Arabic grammar. They can assist the teacher in explaining areas of grammar in context and help students reach conclusions and build patterns/exceptions regarding these areas.
3.5 Limitations of the study
Error analysis as a methodology has been criticised because of the various limitations it poses on sampling, subjectivity, and error categorisation, among other things (Riddell, 1990:28-9). This research has some limitations. There was obvious overlap and difficulty in setting clear boundaries between some types of errors in certain cases. A good example is an error in the idafa construction in الشعب مصر و سوريا/ the people of Egypt and Syria where the first part of the idafa construction must be indefinite: شعب مصر و سوريا / people of Egypt and Syria. This same error can also be classified as an agreement error where the subject agrees with adjective in definitiveness. The phrase could also be written الشعب المصري والسوري / the Egyptian and Syrian people.
In some other cases, a simple change of the grammatical error is not enough such as in the example given about the error of the passive structure (3.3.1.2): […] تم دراستهم النساء أبداً which was corrected to أبداً لم يتم تدريس النساء / women were not educated, however, the whole sentence is to be restructured: لم يتم تدريس (تعليم) النساء أبداً لان مسئولياتهم كانت في المنزل من سن مبكرة / Women were not educated because their responsibilities were looking after the house from an early age. Some of the errors committed are caused because of L1 language interference but it is hard to tell if this is the reason or just lack of competence of the students. What one could say is that it is difficult to fully interpret the reasons behind all errors and such interpretations are only based on the researcher/teacher’s speculations, intuition and experience. What is important to stress, however, is that learning strategies, different training procedures, individual differences of teachers, learners, text books all seem to operate to make each learning situation different from the other (Jain, 1984:190).
In spite of these limitations, the above analysis has helped to give evidence on the most common errors which continue to happen in spite of the fact that they are taught at beginners’ level such as the idafa construction and agreement. The analysis has provided enough evidence that other categories such as prepositions are recurring and they need to be given more attention and to be included in the design of the syllabus and the teaching of Arabic grammar, reading and writing.
REFERENCES
Alhawary, Mohammed T. Modern Standard Arabic Grammar: A Learner’s Guide, (London/New York: Wiley-Blackwell, 2011)
Ashtinay, J.B. Media Arabic, (Edinburgh: Edinburgh University Press, 1993)
Badawi, E., Carter, M.G., and Gully, A. Modern Written Arabic: A Comprehensive Grammar, (New York: Routledge, 2004)
Candlin, C. N., Preface. In Richards, J.C (ed.). Error Analysis Perspectives on Second Language Acquisition, (London: Longman, 1974)
Cook, Vivian, Linguistics and Second Language Acquisition, (New York: Palgrave Publishers Ltd, 1993)
Corder, S. P., ‘Error analysis’, in Techniques in Applied Linguistics, ed. by Allen, J. P. B. & Corder, S. P. (Oxford: Oxford University Press, 1974)
Corder, S. P., ‘The Significance of Learners' Error’, International Review of Applied Linguistics, 5: 161-170, (1967)
Corder, S. P., ‘Idiosyncratic Dialects and Error Analysis’. International Review of Applied Linguistics, 2: 147-160, (1971)
Corder, S. P., Introducing Applied Linguistics. (Harmondsworth: Penguin, 1973)
Corder, S. P., Error Analysis and Interlanguage, (Oxford: Oxford University Press, 1981)
Crystal, D., A Dictionary of Linguistics and Phonetics, 5th ed. (London: Blackwell, 2003)
Dickins, J., ‘Basic Sentence Structure in Sudanese Arabic’, Journal of Semitic Studies LV/1:237-262, (2010)
Dickins, J. ‘Definiteness, Genitives and Two Types of Syntax in Standard Arabic, In: Kuty, R, Seeger, U and Talay, S, (eds.) Nicht nur mit Engelzungen: Beiträge zur semitischen Dialektologie. Festschrift fuer Werner Arnold zum 60, (Geburtstag. Harrassowitz Verlag , 2013)
Dulay, H.C. Burt, M.K. and Kreshen, S., Language Two, (New York: Oxford University Press, 1982)
Ellis, R. The Study of Second Language Acquisition, 2nd ed., (New York: Oxford University press, 2008)
Etherton, A.R.B., ‘Error analysis: Problems and Procedures’, ELT Journal, UK: Oxford Journals, 32 (1):67-78. (1977) <http://eltj.oxfordjournals.org/content/XXXII/1/67.full.pdf> [Accessed 15 April 2015]
Jain, M.P., ‘Error Analysis: Source, cause, and Significance’, in Error Analysis: Perspectives on Second Language Acquisition, ed. by Richards, Jack C., (London: Longman, 1984)
James, Carl, Errors in Language Learning and Use: Exploring Error Analysis, (London: Routledge, 1998)
Jassem, Ali Jassem, Study on Second Language Learners of Arabic: An Error Analysis Approach (Kula Lumpur: A.S. Noordeen, 2000)
Richards, Jack C., ‘Error Analysis and Second Language Strategies’. Language Sciences, 17: 12-22, (1971)
Richards, Jack C., Error Analysis: Perspectives on Second Language Acquisition, (London: Longman, 1984)
Richards, Jack C., et al., Dictionary of Language Teaching and Applied Linguistics, (Essex, Longman, 1992)
Riddell, P., ‘Error Analysis: A Useful Procedure for Identifying Post-testing Activities’, Language Learning Journal, 2:28-32, (1990)
Ryding, C. Karin. A Reference Grammar of Modern Standard Arabic, (London: Cambridge University Press, 2005)
Scott, M. S. and Tucker, R. G. ‘Error Analysis and English-Language Strategies of Arab Students’, Language Learning: A Journal of Research in Language Studies, London: Willey, 24 (1): 69–97, (1974)
Watson, Janet, A Syntax of San’ani Arabic, (Wiesbaden: Harrassowitz, 1993)
FOOTNOTES
[1] Acknowledgment: Thanks are due to Professor James Dickins and Dr Rasha Soliman of the department of Arabic, Islamic and Middle Eastern Studies for reading and commenting on this paper.
[2] For more information on the structure of the programme, refer to this website: http://www.leeds.ac.uk/arts/coursefinder/main/20051/arabic_and_middle_eastern_studies
[3] For more information and examples on adjective-noun agreement, refer to (Ryding, 2005 and Alhawary, 2011:64-70)
[4] For more detailed explanation on the different types of prepositions, see Ryding (2005:366-400), Badawi, Carter and Gully (2004: 174-178), and Alhawary (2011: 119-131).
[5] For more details and examples, see Alhawary (2011: 372-82).
[6] This type of error will not discussed here due to word limitations. For information about Mood in Arabic, see Ryding (2005: 606-15).